Laut dem TIOBE Index ist C selbst heute immer noch eine weit verbreitete Programmiersprache. Viele erfolgreiche Projekte wie Linux, zlib, FreeType, SDL oder auch FFmpeg sind größtenteils oder vollständig in C geschrieben. Gerade im embedded Bereich ist C immer noch sehr weit verbreitet. Jedoch ist es in C vergleichsweise einfach ausnutzbare Sicherheitslücken zu verursachen. Viele Fehler ließen sich aber mit sorgfältiger Planung, Programmierung und dem Wissen über potenzielle Schwachstellen leicht vermeiden. Daher möchte ich hier eine Zusammenstellung von einigen allgemeinen Programmierfehlern aufstellen, die häufig zu Sicherheitslücken führen und wie diese vermieden werden können.
Buffer Overflow
Der Pufferüberlauf ist mit einer der häufigsten und schwerwiegendsten Arten von Speicherfehlern. Bei ein derartigen Fehler ist es einem Hacker sehr einfach möglich eigenen Code auszuführen (in der Praxis wird dies jedoch mit Exploit Mitigations wie ASLR vom Betriebssystem erschwert).
Ein Pufferüberlauf passiert, wenn über die Grenzen eines Arrays bzw. Speicherbereiches hinaus geschrieben wird.
Nehmen wir uns mal folgendes Beispiel vor.
#include <stdio.h>
int main()
{
char username[20];
printf("Bitte Benutzernamen eingeben: ");
scanf("%s", username);
printf("Eingegebener Benutzername: %s\n", username);
return 0;
}Wird in der Abfrage ein Benutzername mit 20 oder mehr Zeichen eingegeben wird über die Grenzen des Feldes hinaus geschrieben und bestehender Speicher überschrieben. Es gibt viele alte C Funktionen im Standard, welche die Größe der Daten nicht prüfen und bei zu langen Eingaben über den Speicherbereich hinaus operieren. Oft genutztes Beispiel wäre strcpy().
Um dies zu vermeiden verwendet man entweder Funktionen, welche die Länge überprüfen (strncpy()) oder überprüft wenn möglich vor der Verwendung die Größe des Puffers und die Größe der Daten.
Bei C ist insbesondere bei Zeichenketten (Strings) zu beachten, dass diese am Ende noch einen zusätzlichen NULL Terminator haben. In Klartext bedeutet das, dass die Zeichenkette „Hallo“ im Speicher als „Hallo\0“ dargestellt wird und somit nicht 5 sondern 6 Bytes groß ist. Dabei sollte auch beachtet werden, dass strlen() die Länge des Strings ohne NULL-Byte zurückgibt.
Eine mögliche abgesicherte Version des obigen Beispiels wäre folgender Code (Edit: Mein Caching Plugin scheint den Code aufgrund des NULL-Bytes etwas zu zerhacken):
#include <stdio.h>
#include <string.h>
int main()
{
const int username_buf_size = 20;
char username[username_buf_size];
printf("Bitte Benutzernamen eingeben: ");
char* get_result = fgets(username, username_buf_size, stdin);
// Überprüfen, ob das Lesen von der Standardeingabe
// funktioniert hat
if(get_result) {
// Ggf Newline Zeichen entfernen
char* newline_char_ptr = strchr(username, '\n');
// Wurde das Newline Zeichen im String gefunden?
if(newline_char_ptr) {
// Newline durch NULL Terminator ersetzen
newline_char_ptr[0] = '#include <stdio.h>
#include <string.h>
int main()
{
const int username_buf_size = 20;
char username[username_buf_size];
printf("Bitte Benutzernamen eingeben: ");
char* get_result = fgets(username, username_buf_size, stdin);
// Überprüfen, ob das Lesen von der Standardeingabe
// funktioniert hat
if(get_result) {
// Ggf Newline Zeichen entfernen
char* newline_char_ptr = strchr(username, '\n');
// Wurde das Newline Zeichen im String gefunden?
if(newline_char_ptr) {
// Newline durch NULL Terminator ersetzen
newline_char_ptr[0] = '\0';
}
else {
printf("Benutzername war zu lang und wurde abgeschnitten!\n");
}
printf("Eingegebener Benutzername: %s\n", username);
}
else {
printf("Fehler beim Auslesen der Benutzereingabe!\n");
}
return 0;
}
';
}
else {
printf("Benutzername war zu lang und wurde abgeschnitten!\n");
}
printf("Eingegebener Benutzername: %s\n", username);
}
else {
printf("Fehler beim Auslesen der Benutzereingabe!\n");
}
return 0;
}Neben den obigen Beispiel gibt es aber auch noch andere mögliche Ursachen für einen Buffer Overflow. Eine Möglichkeit wäre zum Beispiel, dass man eine Funktion gegeben hat, welche einen Pointer und eine size_t Ganzzahl als Parameter akzeptiert. Diese Funktion sendet die Daten hinter dem Pointer zum Client und die Ganzzahl gibt dabei die Größe der Daten an. Wenn der zweite Parameter allerdings aus nicht vertrauenswürdigen Quellen abgeleitet wird kann dies dazu ausgenutzt werden, dass nicht nur die Daten vom Pointer, sondern auch alles was sich im Speicher hinter dem gewünschten Bereich befindet mitgesendet wird. Dies war vereinfacht ausgedrückt die Ursache für die berühmte Heartbleed Lücke in OpenSSL:
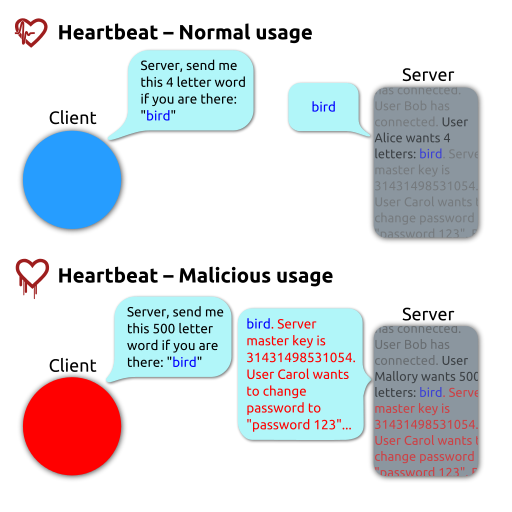
{kind=link}
Daher ist es bei der Programmierung nötig zu überprüfen, wo Daten aus nicht vertrauenswürdigen Quellen verarbeitet werden und wie diese insbesondere bei Fehleingaben den Ablauf des Programms beeinflussen können.
Use after free
In der Praxis kann diese Lücke unter Umständen ebenfalls dazu missbraucht werden um fremden Code auszuführen. Diese ist damit ähnlich gefährlich wie eine Buffer Overflow Lücke.
Diese Lücke tritt vereinfacht gesagt dann auf, wenn man mittels malloc() sich Speicher auf dem Heap reserviert und den Pointer an mehrere Stellen im Programm verteilt. Wenn jetzt eine Stelle den Speicherbereich wieder mit free() freigibt und dann der Pointer an anderen Stellen im Programm benutzt wird greifen jene Stellen auf Speicher zu, welcher eventuell wieder für ganz andere Zwecke reserviert wurde. Es werden also wieder fremde Speicherbereiche ausgelesen oder gar überschrieben.
Folgendes Beispiel veranschaulicht verwundbaren Quellcode.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
// Speicherbereich reservieren
char* username = malloc(20);
// Inhalt setzen
strncpy(username, "TechDragonBlog", 20);
// Inhalt ausgeben
printf("username 1: %s\n", username);
// Speicherbereich freigeben
free(username);
// Alle folgenden Aktionen sind Use after free
// Inhalt ausgeben
printf("username 1: %s\n", username);
// Inhalt setzen
strncpy(username, "UseAfterFreeHere", 20);
// Inhalt ausgeben
printf("username 1: %s\n", username);
return 0;
}Neben diesen einfachen Beispiel gibt es allerdings auch subtilere Wege ein use after free Szenario zu verursachen. Nehmen wir mal an wir haben eine selbst gebastelte String_t Struktur welche intern neben den Pointer zu dem C-String (char*) auch eine Längenangabe enthält. Für diese Struktur gibt es eine Funktion namens append_string() welche einen C-String an die String_t Struktur anhängt. Intern muss dazu erst der Bereich, welcher den C-String enthält vergrößert werden. Dies wird mittels der Funktion realloc() durchgeführt. Bei der Verwendung kann es aber passierten, dass hinter dem Speicher Segment, wo sich der C-String befindet, nicht genug Platz für die hinzuzufügenden Characters ist. In dem Fall verschiebt realloc() den Inhalt in ein neues Speichersegment. Wenn man jetzt also eine Referenz auf den C-String hat und dann etwas über die append_string() Funktion anhängt, dann kann es passieren, dass die Referenz nach dem Anhängen auf den von realloc() freigegebenen Speicherbereich zeigt. Folgendes Codebeispiel veranschaulicht diesen Sachverhalt:
#include <stdbool.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct {
char* data;
size_t str_len;
} String_t;
String_t* init_str(const char* str) {
// Überprüfe auf NULL Pointer
if(!str)
return NULL;
// Länge des Quellstrings bestimmen
size_t str_len = strlen(str);
// Überläufe verhindern
if(str_len == SIZE_MAX)
return NULL;
// Speicherbereich für das String Objekt und die Daten allozieren
String_t* str_obj = malloc(sizeof(String_t));
str_obj->data = malloc(str_len + 1);
// Länge des Strings im Objekt speichern
str_obj->str_len = str_len;
// Quellstring ins Objekt kopieren
strcpy(str_obj->data, str);
return str_obj;
}
bool append_str(String_t* str_obj, const char* str) {
// Überprüfe auf NULL Pointer
if(!str_obj || !str)
return false;
size_t str_len = strlen(str);
// Auf Überlauf überprüfen
if(str_len > SIZE_MAX - str_obj->str_len)
return false;
size_t new_len = str_obj->str_len + str_len;
// Auf Überlauf überprüfen
if(new_len == SIZE_MAX)
return false;
// Speicherbereich vergrößern
char* new_data = realloc(str_obj->data, new_len + 1);
// Überprüfen, on dies erfolgreich war
if(!new_data)
return false;
// Neuen Puffer und Länge im Objekt speichern
str_obj->data = new_data;
str_obj->str_len = new_len;
// Str anhängen
strcat(str_obj->data, str);
return true;
}
void free_str(String_t* str_obj) {
if(!str_obj)
return;
free(str_obj->data);
free(str_obj);
}
int main()
{
// String erzeugen
String_t* teststring = init_str("StringTeil1-");
if(!teststring)
return 1;
// Referenz zu den Daten holen und ausgeben
const char* str_data_ref = teststring->data;
printf("Inhalt: %s\n", str_data_ref);
// String erweitern
append_str(teststring, "StrErweiterung");
// Die Verwendung von str_data_ref ist jetzt
// potentiell use after free
// String über eine gültige Referenz erneut ausgeben
printf("Inhalt neu (richtig): %s\n", teststring->data);
// String über die ungültige Referenz erneut ausgeben
printf("Inhalt neu (falsch): %s\n", str_data_ref);
// Speicherbereich freigeben
free_str(teststring);
return 0;
}
// Ausgaben:
// Inhalt: StringTeil1-
// Inhalt neu (richtig): StringTeil1-StrErweiterung
// Inhalt neu (falsch): �j'[Diesen Programmierfehler zu vermeiden ist in der Praxis schon deutlich schwieriger als mit einem Buffer Overflow. Denn für die Vermeidung des Fehlers aus dem ersten Codebeispiel muss der Programmierer über die Lebenszeit des Speicherbereiches Bescheid wissen. Also wo wird der Speicher mit malloc() alloziert, wo wird der überall verwendet und wann und wo wird der Speicher mit free() wieder freigegeben. Besonders in größeren Codemengen kann es dann vorkommen, dass am Ende nur der ursprüngliche Entwickler einen Überblick üben den Lebenszyklus eines Speicherbereiches hat. Es gibt allerdings verschiedene Möglichkeiten die Problematik einzugrenzen.
Eine Möglichkeit ist bei der Planungs- und Designphase die Lebenszeit und Besitz des Speicherbereiches mit einzubeziehen und zu Dokumentieren.
In der Programmiersprache Rust wird die Lebenszeit von Objekten bereits beim Kompilieren ausgewertet und mögliche use after free oder double free Fehler vermieden. Möglich macht es das Ownership and Borrowing System von Rust. Sehr vereinfacht ausgedrückt heißt es dass nur eine Variable den Besitz des Objektes hat. Übergibt man diese Variable an eine Funktion so wird entweder der Besitz des Objektes an die Funktion übergeben oder ausgeborgt (je nachdem, ob die aufzurufende Funktion das Objekt oder eine Referenz des Objektes als Argument akzeptiert). Im ersten Fall wird die Variable, die man der Funktion übergeben hat ungültig und eine Verwendung dieser nach dem Aufruf führt zu einer Fehlermeldung des Compilers. Im zweiten Fall kann die aufgerufene Funktion das Objekt zwar verwenden, aber nicht davon Besitz ergreifen bzw. diese dauerhaft in ein anderes Objekt speichern. Das geht nur, wenn die aufgerufene Funktion das Objekt mittels .clone() kopiert oder die Lebenszeit aller beteiligten Objekte mittels des Lifetime Operators festlegt. Dieses Design, was vom Rust Compiler forciert wird kann man in C auch durch sorgfältige Planung und Programmierung umsetzen (was in der Praxis aber wohl eher nicht geschieht). Beim zweiten Codebeispiel ist es jedoch leichter den Fehler zu vermeiden. Wenn man sich daran hält nach dem Verändern einer Struktur zuvor ausgelesene Referenzen als ungültig zu betrachten kann man dieser Fehlerquelle aus dem Weg gehen. In Rust kann man vereinfacht ausgedrückt entweder mehrere unveränderliche (also praktisch Read-Only) Referenzen auf ein Objekt haben oder eine veränderliche Referenz (mut&). Beides zusammen geht nicht.
Zu guter Letzt es es auch möglich Tools wie statische Codeanalyse Tools wie CppCheck und Clang-Tidy einzusetzen um solche Fehler aufzuspüren. Jedoch ist dabei zu beachten, dass diese eventuell auch bei korrekten Zeilen anschlagen oder Fehler übersehen können. In meinen einfachen Codebeispielen hat Clang-Tidy die Fehler korrekt erkannt.
Double free
Dieser Fehler ist im Prinzip fast das Gleiche wie ein use after free. Nur wird hier ein bereits mit free() freigegebener Speicherbereich später an anderer Stelle erneut freigegeben. Daher gilt hier in etwa das gleiche, was ich bereits zu Use after free geschrieben habe.
Uncontrolled Format String
In der Praxis werden Log Ausgaben häufig mittels der printf() Funktion nach stdout ausgegeben. Dabei wird zuerst ein Format-String spezifiziert und als weitere Argumente die jeweiligen Daten, die ausgegeben werden sollen. Gefährlich wird es dann, wenn man es sich spart einen Format-String anzugeben und stattdessen den Inhalt eines C-Strings direkt als erstes Argument mitgibt. Kann der Benutzer diesen String beeinflussen ist es möglich Daten vom Stack abzugreifen oder unter Umständen Daten im Speicher zu verändern. Folgendes Codebeispiel veranschaulicht dieses Verhalten:
#include <stdio.h>
int main(int argc, char* argv[])
{
if(argc == 2)
{
printf(argv[1]);
printf("\n");
}
return 0;
}
// Aufruf: ./cplayground "Test: %s"
// Ausgabe: Test: <�T��Die Lösung ist recht simpel. Der Format-String sollte immer direkt im Code definiert werden und nicht von außen kommen. Folgender Code ist gegen diese Schwachstelle abgesichert:
#include <stdio.h>
int main(int argc, char* argv[])
{
if(argc == 2)
printf("%s\n", argv[1]);
return 0;
}
// Aufruf: ./cplayground "Test: %s"
// Ausgabe: Test: %sArithmetischer Integer Overflow
Arithmetische Überläufe entstehen wenn durch eine mathematische Operation der darstellbare Bereich des Datentypes über- oder unterschritten wird. Besonders bei signed Integers ist das ein großes Problem, da dies in C und C++ undefiniertes Verhalten zu Folge hat. Folgendes Beispiel zeigt einen Integer Overflow:
#include <stdio.h>
#include <limits.h>
int main()
{
int test_int = INT_MAX;
printf("test_int: %i\n", test_int);
printf("test_int + 5: %i\n", test_int + 5);
return 0;
}
// Ausgabe
// test_int: 2147483647
// test_int + 5: -2147483644Es gibt aber eine einfache Formel, mit der man überprüfen kann, ob eine Addition oder Subtraktion einen Überlauf auslöst. Angenommen man möchte a und b addieren und beide Variablen hängen von Benutzereingaben oder Daten aus nicht vertrauenswürdiger Quelle ab. Die größt- und kleinstmögliche Zahl im zur Verfügung bestehenden Bereich nennen wir einfach mal N_MAX und N_MIN. Folgende if Bedingung ergibt true, wenn die Addition ohne Überlauf möglich ist:
if(a <= N_MAX - b)Folgendes Codebeispiel fängt Überläufe vor der Addition ab:
#include <stdio.h>
#include <limits.h>
int main()
{
int op1 = INT_MAX - 2;
int op2 = 3; // 2 = ok; 3 = not ok
if(op1 <= INT_MAX - op2) {
printf("Ergebnis: %i\n", op1 + op2);
}
else {
printf("Überlauf!\n");
}
return 0;
}Für Subtraktionen gibt es eine ähnliche Verifikation:
if(a >= N_MIN + b) // Prüft a - b
if(a <= N_MIN + b) // Prüft b - aEs ist allerdings keine gute Idee bei Variablen vom Typ „int“ (also ohne unsigned davor) eine „Verifikation“ nach dem Schema (a + b) > a durchzuführen, da ein Überlauf einer Zahl bei vorzeichenbehafteten Ganzzahlen undefiniertes Verhalten ist und diese „Verifikation“ damit von undefinierten Verhalten abhängt, was ein klares NoGo ist.
Integer Coercion Error
Dieser Fehler tritt dann auf, wenn man eine Dezimalzahl in ein Datentyp umwandelt für welchen die gegebene Zahl zu groß ist. Ebenso tritt dies auf, wenn man eine negative Zahl in einen vorzeichenlosen Datentyp umwandelt (beispielsweise int nach unsigned int). Folgendes Codebeispiel veranschaulicht, was ich damit meine:
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char* argv[])
{
if(argc == 2) {
long int buf_size = strtol(argv[1], NULL, 10);
printf("buff_size: %ld\n", buf_size);
printf("buff_size (als unsigned): %lu\n", (size_t)buf_size);
if(buf_size > 2048) {
printf("Mehr als 2048 ist nicht erlaubt!\n");
return 1;
}
// buf_size wird hier implizit als
// size_t (unsigned long int) gecastet
char* buf = malloc(sizeof(char) * buf_size);
if(buf) {
printf("Allokation erfolgreich!\n");
free(buf);
}
else {
printf("Da ging was schief!\n");
}
}
return 0;
}
// Aufruf: ./cplayground -1
// Ausgaben:
// buff_size: -1
// buff_size (als unsigned): 18446744073709551615
// Da ging was schief!Um diese Fehlerquelle zu vermeiden muss vor einer Umwandlung überprüft werden ob sich die umzuwandelnde Zahl im Bereich des Zieldatentypes befindet. Der Code muss also folgendermaßen aussehen:
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char* argv[])
{
if(argc == 2) {
long int buf_size = strtol(argv[1], NULL, 10);
printf("buff_size: %ld\n", buf_size);
printf("buff_size (als unsigned): %lu\n", (size_t)buf_size);
if(buf_size > 2048) {
printf("Mehr als 2048 ist nicht erlaubt!\n");
return 1;
}
else if(buf_size <= 0) {
printf("0 und negative Zahlen sind nicht erlaubt!\n");
return 1;
}
// buf_size wird hier implizit als
// size_t (unsigned long int) gecastet
char* buf = malloc(sizeof(char) * buf_size);
if(buf) {
printf("Allokation erfolgreich!\n");
free(buf);
}
else {
printf("Da ging was schief!\n");
}
}
return 0;
}
// Aufruf: ./cplayground -1
// Ausgaben:
// buff_size: -1
// buff_size (als unsigned): 18446744073709551615
// 0 und negative Zahlen sind nicht erlaubt!Division by 0
Wenn bei einer Division durch 0 geteilt wird stürzt das Programm ab was für DoS Angriffe ausgenutzt werden kann. Daher sollte der Divisor vor der Operation auf 0 geprüft werden. Folgender Code verzichtet auf eine derartige Prüfung und stürzt demnach bei entsprechenden Eingaben ab.
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char* argv[])
{
if(argc == 2) {
long int user_input_number = strtol(argv[1], NULL, 10);
printf("10 / x = %ld\n", 10 / user_input_number);
}
return 0;
}
// Aufruf: ./cplayground 0 oder ./cplayground Müll
// Ausgabe: Gleitkomma-Ausnahme (Speicherabzug geschrieben)Um den Code abzusichern muss man nur die Variable user_input_number nach der Definition auf 0 prüfen.
Uninitialisierte Variable verwenden
Wenn man in C eine Variable definiert und dieser keinen Wert zuweist, dann ist der Inhalt bzw. das Benutzen dieser Variable undefiniertes Verhalten. Hier sieht man einen Fehler dieser Art im Code:
#include <stdio.h>
int main()
{
int test_var;
printf("Inhalt test_var: %i\n", test_var);
return 0;
}
// Ausgabe: Inhalt test_var: 0In diesem Beispiel ist das zwar noch gut gegangen (der Inhalt der Variable war immer 0), dies kann in der Praxis jedoch anders sein. Daher sollte man beim Definieren der Variablen ihr auch gleich einen Wert zuweisen. Aus „int test_var;“ wird demnach „int test_var = 0;“.
NULL Pointer Dereferenzierung
Einige Funktionen geben bei Operationen im Erfolgsfall einen Pointer auf eine Datenstruktur zurück und im Fehlerfall kommt ein NULL Pointer zurück. Der Rückgabe Wert muss dann in diesem Szenario vor der Verwendung überprüft werden. Folgendes Codebeispiel macht diese Prüfung nicht und stürzt daher ab.
#include <stdio.h>
#include <stdlib.h>
typedef struct {
long int pre_decimal;
unsigned char post_decimal;
} BankBalance;
BankBalance* bankbalance_create(long int pre_decimal, unsigned char post_decimal) {
if(post_decimal >= 100)
return NULL;
BankBalance* balance = malloc(sizeof(BankBalance));
balance->pre_decimal = pre_decimal;
balance->post_decimal = post_decimal;
return balance;
}
int main(int argc, char* argv[])
{
BankBalance* my_money = bankbalance_create(120, 100);
// Crash, da my_money NULL ist
printf("Kontostand: %ld,%d\n", my_money->pre_decimal, my_money->post_decimal);
free(my_money);
return 0;
}
// Ausgabe: Speicherzugriffsfehler (Speicherabzug geschrieben)Um diesen Fehler zu vermeiden genügt es wie im folgenden Beispiel die entsprechende Rückgabe zu überprüfen.
#include <stdio.h>
#include <stdlib.h>
typedef struct {
long int pre_decimal;
unsigned char post_decimal;
} BankBalance;
BankBalance* bankbalance_create(long int pre_decimal, unsigned char post_decimal) {
if(post_decimal >= 100)
return NULL;
BankBalance* balance = malloc(sizeof(BankBalance));
balance->pre_decimal = pre_decimal;
balance->post_decimal = post_decimal;
return balance;
}
int main(int argc, char* argv[])
{
BankBalance* my_money = bankbalance_create(120, 100);
if(my_money) {
printf("Kontostand: %ld,%d\n", my_money->pre_decimal, my_money->post_decimal);
free(my_money);
}
else {
printf("BankBalance Objekt konnte nicht erzeugt werden!\n");
}
return 0;
}
// Ausgabe: BankBalance Objekt konnte nicht erzeugt werden!Command Injection
In C kann man mit der system() Funktion Kommandobefehle ausführen. Kritisch wird es dann, wenn der auszuführende Befehl sich von Daten aus nicht vertrauenswürdigen Quellen ableitet. In so einem Fall kann der Angreifer beliebige Befehle mit den Rechten des entsprechenden Benutzers, unter dem der Prozess läuft, ausführen. Folgendes vereinfachtes Beispiel demonstriert dies:
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char** argv)
{
char command[300];
if(argc == 2) {
snprintf(command, 300, "ffprobe -hide_banner %s", argv[1]);
system(command);
}
return 0;
}
// Aufruf: ./cplayground "06-Omnibus.flac && echo You got owned!"
// Ausgaben:
// [Ausgaben von ffprobe]
// You got owned!Grundsätzlich ist es ratsam ein solches Szenario, dass eine Kommandozeilenanweisung von Benutzereingaben abhängt komplett zu vermeiden. Die Chance, dass man bei sowas eine Sicherheitslücke verursacht ist recht hoch. Falls es dennoch keine Alternative gibt gilt es die altbekannte Regel „Überprüfe alle Benutzereingaben“ sorgfältig anzuwenden. Dazu ist es am einfachsten eine Whitelist mit erlaubten/ungefährlichen Zeichen zu machen. Dafür muss man aber wissen, welche Zeichen gefährlich werden können. Für Bash gibt es bereits eine solche Liste an der man sich orientieren kann (Link). Wenn man beispielsweise ein Benutzernamen erwartet liegt es Nahe die Eingabe auf ASCII Buchstaben im Alphabet und Zahlen zu beschränken. Der folgende Code überprüft die Eingabe auf Validität und bricht mit einer Fehlermeldung ab, falls diese nicht erlaubte Zeichen enthält:
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <string.h>
// Erlaube A-Z, a-z, 0-9, '-', '_', '.', ' '
// und 0 oder 2 mal '"'
bool validate_input(const char* input) {
unsigned int dq_count = 0;
size_t input_len = strlen(input);
for(size_t i = 0; i < input_len; i++) {
const char current_char = input[i];
if(current_char >= 'A' && current_char <= 'Z')
continue;
if(current_char >= 'a' && current_char <= 'z')
continue;
if(current_char >= '0' && current_char <= '9')
continue;
if(current_char == '-')
continue;
if(current_char == '_')
continue;
if(current_char == '.')
continue;
if(current_char == ' ')
continue;
if(current_char == '"') {
dq_count++;
continue;
}
return false;
}
if(dq_count == 0 || dq_count == 2)
return true;
return false;
}
int main(int argc, char** argv)
{
char command[300];
if(argc == 2 && validate_input(argv[1])) {
snprintf(command, 300, "ffprobe -hide_banner %s", argv[1]);
system(command);
}
else {
puts("Ungültige Eingabe!");
}
return 0;
}
// Aufruf: ./cplayground "06-Omnibus.flac && echo You got owned!"
// Ausgabe: Ungültige Eingabe!Generell ist es aus sicherheitstechnischer Sicht besser so wenig wie möglich zuzulassen oder wenn möglich auf für Injection anfällige Konstrukte komplett zu verzichten. Außerdem sollte beim Treffen auf ungültige oder gefährliche Zeichen in den meisten Fällen nicht versucht werden diese irgendwie zu entschärfen. Stattdessen sollte eine ungültige Eingabe lieber direkt abgelehnt werden.
In der Praxis kam diese Art von Sicherheitslücke im Jahre 2014 in Bash vor. Die Rede ist hier von der berühmten Shellshock Sicherheitslücke. Diese lässt sich vereinfacht folgendermaßen zusammenfassen:
Bash erlaubte die Ausführung von beliebigen Code aus nicht vertrauenswürdigen Quellen. In dem Fall war die Quelle die Umgebungsvariablen. In diese kann ein beliebiger Benutzer beispielsweise bei CGI Webservern beliebige Daten hineinschreiben. Wenn also an irgendeinen Punkt in der Kette Bash aufgerufen wird, dann erbt Bash die präparierte Variable und führte automatisch den darin enthaltenden Code aus.
Neben der Command Injection gibt es noch zwei ähnliche Attacken die vor allem in der Web Programmierung eine Rolle spielen. Zum Einen gibt es die SQL Injection bei der durch das Einspeisen von präparierten Werten beliebige SQL Abfragen durchgeführt werden können. Diese können in der Praxis mittels Prepared Statements oder der Verwendung eines ORMs abgewehrt werden.
Zum Anderen gibt es XSS (Cross Site Scripting) bei der in zum Beispiel einem Kommentarfeld präparierter Text, welcher JavaScript enthält, eingegeben wird. Wenn die Webseite dies nicht abfängt wird dieser Code bei jeden Besucher, bei dem der präparierte Kommentar angezeigt wird, ausgeführt. Dies lässt sich beispielsweise zum Stehlen der Session Cookies nutzen. Zwar lässt sich das Abzapfen der Session mittels HttpOnly Flag im Cookie erschweren, aber es gibt dennoch Wege dies zu umgehen (zumal das Stehlen von Session Cookies nicht das Einzige ist wofür sich dieser Angriff nutzen lässt). Daher muss eine Benutzereingabe vor der weiteren Verarbeitung genau überprüft werden. Für genauere Informationen dazu gibt es folgende Orientierungshilfe.
Memory Leaks
Speicherlecks treten dann auf, wenn ein Speicherbereich mit malloc() reserviert wird, aber später nicht mit free() wieder freigegeben wird. Dadurch steigt der Speicherverbrauch des Programms über die Zeit immer weiter an. Die kann dazu führen, dass das gesamte System stark verlangsamt wird, da immer weniger Speicher für andere Prozesse verfügbar ist und das System versucht immer mehr vom Speicher auf die Festplatte oder SSD auszulagern. Damit kann ein solcher Fehler effektiv für DoS Angriffe ausgenutzt werden. Folgendes Video veranschaulicht dieses Verhalten: YouTube-Link. Im Code sieht das im Video gezeigte Verhalten folgendermaßen aus:
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char* argv[])
{
for(int i = 0; i < 10; i++) {
char* debug_string = malloc(sizeof(char) * 200);
sprintf(debug_string, "Schleife mit i = %d", i);
puts(debug_string);
}
return 0;
}
// Ausgaben (Auszug):
// Schleife mit i = 0
// Schleife mit i = 1
// ...Anhand der Ausgaben lässt sich der Speicherleck nicht erkennen. Erst wenn man das Programm mit Heaptrack oder Valgrind analysiert wird das Verhalten deutlich. An der Stelle hätte ich gerne einen Screenshot von Heaptrack gezeigt, in dem Speicherlecks aufgezeigt werden. Aber Heaptrack 1.2.0 funktioniert nicht in Verbindung mit GCC 11.1 Daher nehme ich einfach Valgrind, was folgendes ausgibt:
Aufruf: valgrind --leak-check=full ./cplayground
Ausgaben (Auszug):
==12408== HEAP SUMMARY:
==12408== in use at exit: 2,000 bytes in 10 blocks
==12408== total heap usage: 11 allocs, 1 frees, 3,024 bytes allocated
==12408==
==12408== 2,000 bytes in 10 blocks are definitely lost in loss record 1 of 1
==12408== at 0x483E7C5: malloc (vg_replace_malloc.c:380)
==12408== by 0x10917A: main (main.c:7)
==12408==
==12408== LEAK SUMMARY:
==12408== definitely lost: 2,000 bytes in 10 blocksWie man sehen kann hat mein Beispielprogramm 2000 Bytes verbraten (200 Bytes pro Schleifendurchlauf).
Um diesen Fehler zu vermeiden ist es ratsam schon bei der Programmierung darauf zu achten, dass man ein mit malloc() reservierten Speicherbereich später in allen möglichen Szenarien mit free() wieder freigibt. Zudem muss man beim Aufrufen von manchen Funktionen darauf achten, dass diese intern Ressourcen allozieren. Dieser müssen später wieder freigegeben werden. Ein Beispiel wäre das Erzeugen einer Postgres Verbindung mit der Bibliotheksfunktion PQconnectdb() aus der libpq, welche später wieder mit PQfinish() freigegeben werden muss. Zusätzlich lohnt es sich das Programm mit Valgrind und Heaptrack zu testen. Diese beiden Tools beobachten das zu testende Programm während es läuft und zeigen später die Stellen auf, wo Speicher alloziert wurde, welcher später nicht wieder freigegeben wurde. Um den oberen Beispielcode zu korrigieren genügt es „free(debug_string);“ ans Ende der for Schleife einzufügen.
Zusammenfassung
Wie man hier sehen kann gibt es viele Dinge, auf die man bei der Programmierung in C achten muss um die Software möglichst sicher zu halten. Wer ernsthaft vor hat in C zu programmieren sollte sich aber definitiv noch weiter mit der Thematik der Sicherheit auseinandersetzen. Zwei definitiv lesenswerte Ressourcen dazu sind die CWE und das Buch „24 Deadly Sins of Software Security„. Sofern es die Anforderungen zulassen ist aber ratsam auf speicher-sichere Programmiersprachen wie Rust, Java, Go, Python, Javascript, etc zu setzen. Selbst die Verwendung von modernen C++ hilft ein Teil der Fehlerquellen zu vermeiden.
Neben den bestmöglichen Anstrengungen Programmierfehler zu vermeiden gibt es aber auch noch weitere Möglichkeiten (Compiler Optionen, Beschränkung der Rechte im Betriebssystem, Separierung der Rechte, etc.) die Sicherheit von C Programmen zu verbessern. Dies sprengt aber den Rahmen dieses Artikels und wird daher Stoff für weitere Artikel dieser Serie.
2 Antworten auf „Programmieren in C: Sicherheit Teil 1“
Es ist IMNSHO niemals ratsam, auf Python zu setzen. Python ist eine unfassbar unperformante Sprache mit widerlicher Syntax.
Auch Java (fehlende Speicherverwaltung = Bloat) und JavaScript (http://www.tamagothi.de/2011/09/13/warum-javascript-unbrauchbar-ist/) sind die Pest.
YMMV.
>Python ist eine unfassbar unperformante Sprache
Es gibt Projekte in denen die Performance eher nebensächlich ist. Ich weiß zum Beispiel von einer internen Verwaltungsoftware in einen Studentenwohnheim die in Python mit dem Django Framework geschrieben ist. Diese interne Seite muss nur mit sehr wenig Besuchern klarkommen. Daher spielte die Performance da kaum eine Rolle. Die Entwicklungsgeschwindigkeit war da viel wichtiger.
>widerlicher Syntax.
Meiner Meinung nach ist die Syntax recht leicht zu lernen. Meistens ist das aber auch eine Gewöhnungssache. Auf 4chan /g/ wird gern geschrieben, dass Rust eine grauenhafte Synthax habe. Für jemanden der nie damit gearbeitet hat mag das eventuell stimmen. Ich habe mich aber nach recht kurzer Zeit daran gewöhnt und kann in Rust relativ fix brauchbare Sachen zusammenbasteln.
>Java
Wenn ich Apps für Android programmieren würde, wäre Java oder Kotlin meine erste Wahl. Ansonsten steht es auch mit der Performance bei Java gar nicht so schlecht. Zwar ist Java bei weitem nicht so schnell wie C/C++, aber dennoch deutlich besser als Python. Allerdings ist der RAM Verbrauch von Java Anwendungen deutlich höher.
>fehlende Speicherverwaltung = Bloat
Wenn es die Performanceanforderungen zulassen spielt der Bloat durch den Garbage Collector eher kaum eine Rolle. Es gibt natürlich auch Projekte, wo eine Sprache mit GC fehl am Platz ist. Die Erfahrung hatte Discord bereits gemacht (https://blog.discord.com/why-discord-is-switching-from-go-to-rust-a190bbca2b1f).
>Javascript
Hab ich in der Praxis noch nicht großartig verwendet, aber zum Verarbeiten von JSON Daten vom Backend und Verändern des Seiteninhaltes über die DOM API reicht es. Ich finde es eher bedenklich, dass JS mittels NodeJS auch in andere Bereiche als die Webprogrammierung gepusht wird. Und das Ökosystem der Abhängigkeiten ist komplett aus dem Ruder gelaufen.